为深度学习推断对比 VPU、GPU 和 FPGA

简介
开始机器视觉深度学习的一个关键决策是选择用于推断的硬件类型。图形处理器 (GPU)、现场可编程门阵列 (FPGA) 和视觉处理器 (VPU) 均存在影响您系统设计的优势和劣势。本文将探索这些特质,并探究评估最适合您应用的平台的方法。
GPU
GPU 的大规模平行架构最适合深度学习推断的加速。Nvidia 深入研究了在其 CUDA(同一计算设备架构)内核中运行深度学习和推断的工具。Google 深受欢迎的 TensorFlow 正式版 GPU 支持面向启用 Nvidia CUDA 的 GPU。一些 GPU 具备数千个处理器内核,最适合计算要求高的任务,例如自主车辆导引以及部署于性能较弱硬件上的训练网络。GPU 的功耗通常较高。RTX 2080 功耗要求为 225W,Jetson TX2 功耗要求为 15W 以上。GPU 也比较昂贵。RTX 2080 价格为 800 美元。
FPGA
FPGA 广泛使用在传统机器视觉工业。众多机器视觉相机和图像采集卡均基于 FPGA。FPGA 具有运行于通用 CPU 的软件灵活性和可编程性,也具有定制设计的专用集成电路(ASIC)的速度和功率效率,处于一种“中间地带”。一款基于 FPGA 的 Intel®™ Aria 10 PCIe 视觉加速卡功率高达 60W,价格为 1500 美元。
FPGA 的一个缺点是其编程需要高度专业技能。开发 FPGA 神经网络复杂度高且耗时长。 虽然开发者可以使用第三方工具简化任务,但这类工具通常比较昂贵,而且会使其陷入专利技术的封闭生态系统中。
VPU
视觉处理单元是一类专用于获取和解读视觉信息的片上系统 (SOC) 。它们专门用于移动应用程序,针对小尺寸和功率效率的进行了优化。Intel® Movidius™ Myriad™ 双 VPU 是其中一个典型代表,它可与 CMOS 图像传感器 (CIS) 交互,对已获取的图像数据进行预处理,然后通过预训练的神经网络传递结果图像,最终输出结果,功耗低于 1 W。Intel 的 Myriad VPU 通过结合传统 CPU 内核和矢量处理内核来为深度神经网络典型的高度分支逻辑关系进行加速,从而实现以上功能。
VPU 非常适合嵌入式应用。它虽然没有 GPU 强大,但因为尺寸小、功率效率高,可设计为极小型系统的内置处理器。 例如,即将推出的 FLIR Firefly 相机便内置了 Myriad 2 VPU,体积不到标准“冰块”机器视觉相机的一半。VPU 的功率效率使其非常适用于亟需长效电池的手持、移动或无人机安装设备。
Intel 为其 Movidius Myriad VPU 创建了一个开放式生态系统,帮助用户按需选择使用深度学习构架和工具链。Intel Neural Compute Stick 配备 USB 接口,价格为 80 美元。
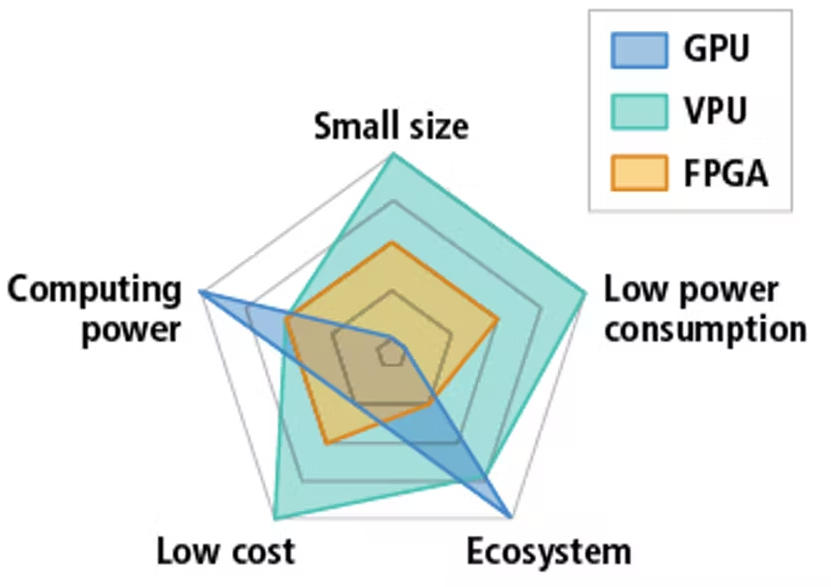
图 1.用于加速推断的常见硬件的相对性能
评估不同硬件性能
由于 GPU、SOC 和 VPU 架构差别,通过每秒浮点运算次数(FLOPS)进行的性能对比没有实际价值。对比已发布的推断时间数据可作为有效起点,但仅仅通过推断时间可能造成误导。虽然 Intel Movidius Myriad 2 的单帧推断时间比 Nvidia Jetson TX2 快,但 TX2 可以同时处理多个帧,从而产生更大的吞吐量。TX2 可同时进行其他计算任务,Myriad 2 则不行。当前,如缺少测试,对比就没有捷径。
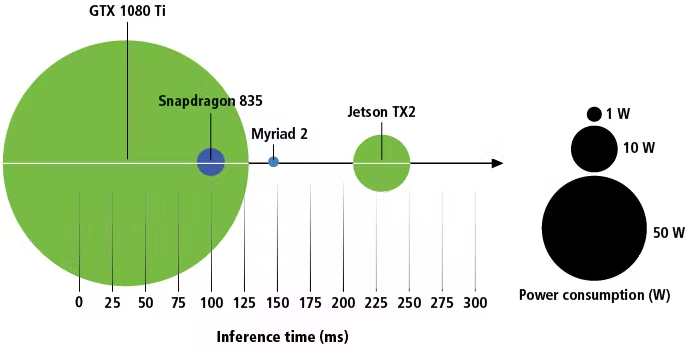
图 2功耗 vs 单帧推断时间
结论
在为支持推断的视觉机器系统选择提供强劲性能的硬件之前,设计者需进行测试以确定应用所需的精度和速度。这些参数将决定所需神经网络的特性以及可以部署的硬件。